
ROBOTS文件和META ROBOTS
发表于 2019-08-21 20:54

ROBOTS文件(robots.txt)是位于网站根目录的文件,也称为机器人排除协议或标准,它告诉搜索引擎网站哪些页面要抓取,哪些页面不抓取。 META ROBOTS是一个元标记,可以单独写入网页。 它也是一个计算机程序,为搜索引擎提供阅读网页的指导。
您无需任何技术或经验即可充分利用robots.txt的强大功能。 您可以通过查看网站来源找到robots.txt。 我们先来看看为什么robots.txt文件如此重要。
什么是robots.txt
robots.txt是网站管理员创建的文本文件,用于告诉网络机器人(通常是搜索引擎机器人)如何抓取其网站上的网页。robots.txt文件是机器人排除协议(REP)的一部分,该协议是一组WEB标准,用于管理机器人如何抓取网络,访问和索引内容,以及将内容提供给用户。REP还包括诸如META ROBOTS之类的指令,以及关于搜索引擎应如何处理链接(例如“follow”或“nofollow”)的网页,子目录或站点范围的指令。
ROBOTS文件基本格式看起来像这样:

下面两个被认为是完整的robots.txt文件,尽管一个robots文件包含多行用户代理和指令(即禁止,允许,爬行延迟等)。
下面这个例子在robots.txt文件中,每组用户代理指令显示为离散集,由换行符分隔:
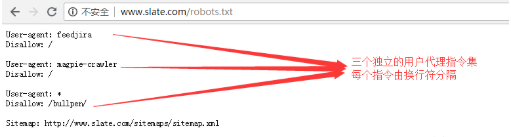
在多个用户代理指令的robots.txt文件中,每个禁止或允许规则仅适用于在该特定行分隔符集中指定的用户代理。如果文件包含多个用户代理的规则,则搜索引擎程序将关注(并遵循指令)最具体的指令组,例子如下:
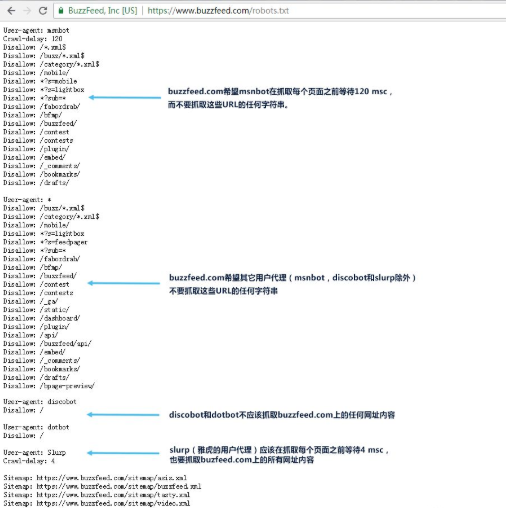
robots.txt重要性
网站使用robots.txt几个重要原因:
希望在搜索引擎中隐藏或阻止网站中的文件;
使用广告时需要特别说明;
希望网站遵循谷歌优化指南以提升SEO。
需要强调的是,一些网站可能觉得不需要robots.txt,因为他们不需要在公共视野中隐藏网站的敏感数据,允许GOOGLEBOT从内到外全面抓取整个网站,如果网站没有robots.txt,则默认搜索引擎可以访问全网站。
如果你正在摸不着头脑,为什么robots.txt会这么好奇,一定要理解这个文件内容的重要性:
它控制搜索引擎如何抓取和网页交互;
它是搜索引擎工作流程中的基本部分;
robots.txt使用不当可能会损害网站搜索排名;
使用robots.txt是谷歌优化指南的一部分。
主要的搜索引擎和大多数信誉良好的小型搜索引擎都会阅读robots.txt的内容,并遵循网站robots.txt的指示来读取网站。优化robots.txt的方式取决于你网站上的内容,使用robots.txt有各种各样的方法。
最常用的robots.txt优化方法
robots.txt最常见的使用方法是屏蔽搜索引擎,不要抓取不希望索引的网站区域,提供xml站点地图访问路径,robots.txt放在网站根目录,以下为例。
第一种:屏蔽不想被搜索引擎编入索引的区域

代码解释:
第一行、用户代理,*意思是允许所有搜索访问;
第二行、告诉搜索引擎不要抓取和收录/private文件夹。
第二种:指定GOOGLEBOT搜索引擎不能够访问和收录/private文件夹

代码解释:
第一行、用户代理,意思是指定Googlebot搜索引擎;
第二行、告诉Googlebot搜索引擎不要抓取和收录/private文件夹。
第三种:网站屏蔽所有搜索引擎

代码解释:
第一行、用户代理,*意思是所有搜索引擎;
第二行、告诉搜索引擎不要抓取和收录网站所有的文件和文件夹。
上述三种情况注意到,如果在robots.txt中乱写一些东西,对网站伤害很大。Disallow:/*这个指令就是网站屏蔽所有搜索引擎。如果网站使用该指令搜索引擎会从索引中删除网站,所以一定要小心。
经典的robots.txt示例
在实际操作中最经典的robots.txt应包含以下内容:

代码解释:
第一行、用户代理,*意思是所有搜索引擎;
第二行、允许所有搜索引擎访问你的网站没有任何屏蔽;
第三行、指定网站地图位置以便搜索引擎更容易找到它。
测试和验证robots.txt
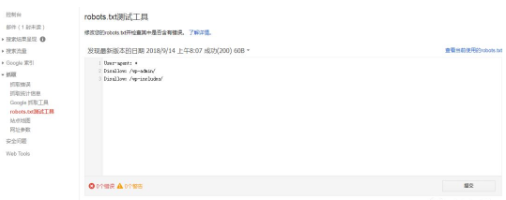
虽然我们可以通过浏览器访问robots.txt网址查看robots.txt的内容,但测试和验证它的最佳方法是通过GOOGLE SEARCH CONSOLE的robots.txt测试程序。
登录你的GOOGLE SEARCH CONSOLE帐户;
点击在抓取选项下找到的robots.txt测试工具;
单击“测试”按钮。
如果一切正常,“测试”按钮将变为绿色,按钮文字变为“已允许”。如果出现问题,将突出显示导致禁用行。
robots.txt在SEO中最佳实践
robots.txt是一个不安全的文件系统,不是真正的文本请求提供给机器人,没有任何方法迫使他们遵守规则。因此网站非常重要区域,robots.txt的disallow不能够帮你实现这一目标。
不要用robot.txt屏蔽js和css文件和文件夹
告诉搜索引擎如何找到网站地图指令sitemap:http://www.yourdomain.com/sitemap.xml
ROBOTS元标签
ROBOTS元标签基本格式看起来像这样:

四种用法:
Index = "请收录这个页面"
Follow ="请追踪此页面上的链接"
Noindex="请不要将此页面编入索引"
Nofollow="请不要追踪此页面上的链接"
所以不要太担心robot.txt文件或者ROBOTS元标签。
您无需花费太多时间配置或测试robots.txt,通过Google网站管理员工具测试并测试是否阻止搜索引擎抓取工具访问您的网站非常重要。











评论 (0人参与)
最新评论