
怎样重构SEO优化
发表于 2019-07-23 22:11
最近,小猪站长一直在重构原来的SEO项目。已经进入了重构的后期阶段。想与您分享整个重构的细节。希望能帮助大家。
什么是SEO项目
SEO(Search EngineOptimization),搜索引擎优化,利用搜索引擎的规则(目前主要指Google)来提高网站在搜索引擎中的自然排名和网站的品牌影响力。用户在搜索引擎上搜索对应的关键词,点击搜索结果直接跳转到SEO登陆页面(登陆页面),然后使用登陆页面将流量引导到需要推广的网站,将流量转化为订单。SEO项目主要根据不同的推广维度设计相应的登陆页面,并为这些登陆页面提供相应的数据。目前,该项目主要覆盖酒店和机票两条主要生产线,以后可能会接入更多的生产线。
为什么要重构
对于原始SEO项目,主要存在以下问题:
代码耦合
端代码和服务器端代码都耦合在同一个项目中。它们在开发过程中相互依赖。页面信息是模块化的、可配置的,并支持一系列功能,如AB测试。
现数据存储
SEO项目的数据存储在与其他系统相同的数据库中,其中一些数据表是共享的,这不可避免地会导致某些表中的字段从SEO项目的角度看是无用的,但不能删除。
数据更新
数据更新一次,大概2-3天。整个过程需要人工干预。如果在更新过程中出现任何问题,则需要完全重新更新,并且仍然存在脏数据。有两种主要类型:一种是数据表。字段的值部分正确,该部分不正确;另一种是数据不完整,例如:如果城市中没有酒店或机场,那么城市数据就没有意义,因为它是在城市维度中。在促销时,没有城市以下酒店或机场的数据。
需求无法满足
在SEO页面的底部,需要根据一定的规则计算相关的链接信息。某一地点的某条生产线用某一种语言生产大约需要4个小时。共有16个站点,每个站点有15种语言和3条生产线,计算所有站点下所有语言和生产线的链接信息需要16*15*3*4=2880小时(120天)。显然,目前的实现方案无法满足。业务需求。
为什么会存在以上这些问题?主要原因如下:
需求迭代太快
IBU一直处于快速发展的状态。很多需求需要在短时间内完成,很难把握未来需求的变化。在提出需求的过程中,不可避免地要选择一些短期的、试探性的、快速有效的解决方案。
开发人员少
在重构之前,整个SEO项目只完成了1-2人的全部开发工作。当需求源不断出现时,开发人员将不可避免地措手不及,不应不知所措。
数据复杂
目前,SEO几乎需要所有与机票和酒店相关的数据,这些数据的收集过程极其分散、复杂和繁琐。在收集一段数据时,可能需要从多个数据源收集数据来收集该数据。所有字段都已完成,数据量大,更新时间长,数据间相关性高,使得数据更新过程更加难以保证数据的完整性。
技术选型
项目的技术选型对整个项目非常重要。这里主要表达的是服务器的技术选型(前端技术选型主要由王贵阳团队负责)。
开发语言
删除的部分代码是用Java实现的,部分代码是用PHP实现的,开发语言统一为Java。主要原因是该公司正在推广Java语言,而所有团队成员最熟悉的编程语言是Java。
数据存储
在数据存储方面,主要使用MySQL数据库,前一部分数据被ES存储删除,另一部分是MySQL存储。在SEO项目中,酒店拥有的数据量最大,只有数千万。对于MySQL,没有任何问题。
RPC框架
公司提供了两种对外公开服务的方法,一种通过Baiji合同公开,另一种来自CDubbo。不选择后者的主要原因是当时刚刚推出,稳定性可能略差于前者。同时,整个团队对前者有了更深入的了解和更多的使用,降低了学习成本。
设计方案
SEO项目的整体架构如下图所示:
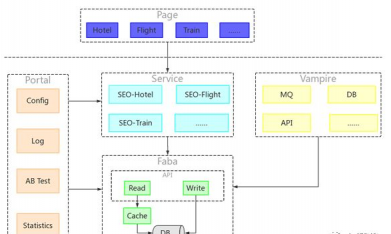
1、Vampire
主要用于采集数据并将其转换为格式化数据。收集数据有两种方法:增量式和完全式。数据源可以是MQ、DB和API(稍后将连接更多数据源)。其核心思想是从不同数据源提取数据,并发地将数据转换为格式化数据,然后调用Faba的写接口将数据写入数据库。
由于完整数据量的数据量很大,因此在整个过程中提取完整数据量是最复杂的。从当前的观点来看,绝大多数的更新完整的数据量是调用API,您需要考虑的每秒调用的API,响应时间,更新时间间隔,API返回消息大小(在某些情况下需要考虑分页),API超时,网关超时,网络带宽、数据之间的依赖关系等,来确定线程的数量,称为频率、周期,呼叫时间(通常称为非高峰时间),以及Vampire调用API时的部署时间。虚拟机的机器数量、CPU内核数量、内存大小等都需要优化不同的参数来调用不同的api。增量更新相对简单。主要采用MQ连接方式。它需要首先考虑发送的消息,然后再考虑发送的消息、重复消息、消息丢失、MQ中的队列大小,等等。在提取数据的过程中,还需要考虑数据提供者可能有脏数据或者不能支持Vampire带来的流量。因此,它还需要支持暂停、恢复和强制更新等功能。
无论它是增量的还是全面的数据拉取,最后需要转换成格式化的数据并写入数据库,这个转换过程的处理速度都是至关重要的,因为吸血鬼实际上是一个生产者和消费者作为一个整体。模型中,生产者是对各种不同数据源的访问,消费者是对提取的数据进行转换,然后调用Faba提供的写接口,快速完成数据转换工作。理想情况下,生产者的生产速度等于消费者的消费速度。当生产速度大于消耗速度时,未生产和消耗的数据会积累在内存中,容易导致OOM,所以实际使用时。一般来说,消费速度大于生产速度。对吸血鬼来说,生产者的速度是交通访问每个数据源的总和,并增加增加的数据源,但消费者的消费能力是固定的,为了提高整个吞吐量的数据收集和转换,它本质上是增加消费者的速度,也就是说,增加的速度较好写接口(较好的机制来处理数据稍后会详细解释)。目前,生产环境中部署了4台8核8G虚拟机。吸血鬼的处理能力可以达到每秒10K+,处理1000W的数据大约需要30分钟。
2、Faba
这个子项目主要是为整个SEO项目提供数据读写操作。写接口主要由Vampire调用来补充数据。Vampire将通过调用Faba的写接口将数据写入数据库来收集和转换数据。Read接口主要用于提供对服务调用的数据的访问。
写接口主要以异步方式实现。当调用Vampire时,数据临时存储在消息队列中,然后使用数据。该处理的优点是:首先提高了写接口的QPS和响应时间。其次,可以将一些相同的操作组合到批处理操作中,以最小化DB连接的消耗。最后,尽可能多地对一个批中写入的数据进行重复删除,以减少不必要的写入。
进入操作。写接口的设计需要考虑三个因素:
一、支持幂等
由于写入的数据来自消息队列,因此消息队列将具有重试机制,因此在写入时需要支持幂等性。事实上,消息队列不能保证数据以有序的方式到达。是否到达有序仅影响的数据增量提取数据,对完整的提取数据没有影响,因为当被全面的数据,每个数据是只有当只拉一次,每一块数据的更新操作是相互独立的,没有考虑订单。增量提取数据,假设一个城市数据更改城市名从a到B的同时,然后从B到C,两个更新将被推到吸血鬼以有序的方式,然后吸血鬼将格式化的数据后,调用单写接口。当从消息队列中使用这两个数据时,可以先接收城市名从B更改为C的数据,然后接收从A修改为B的数据。此时,将修改这两个数据的时间用作时间戳。数据库中的数据更新时,只更新当前的时间戳,而大于数据库中的数据的更新时间,剩下的都过滤掉,也就是说,这个城市的名字是B数据修改C将更新数据库,从A到B和数据修改将会被过滤掉。
二、消费速率
很容易看出,整个写过程的瓶颈是DB写操作。公司DB的连接池大小为100,这意味着消息队列中的数据被多线程使用,线程池的大小不应该超过100。消费者的消费能力是确定的。生产者的生产能力只能通过简单的计算来确定。理论上,只有生产者单位时间内的生产数据总量等于消费者线程数100*每批。内部数据的平均数量,这只是一个理想的情况,实际情况可能需要考虑三个因素:
1)消息队列的大小,即存储数据的能力,与机器内存有关;
2)可接受的数据延迟时间,即从消息队列的一个条目到写入DB的时间;
3)输入输出处理能力、数据写入到数据库将生成大量的IO操作,尤其是在批量写操作,因为之前没有考虑这一因素,导致其他SEO DB在同一物理机器上大量的超时报警发生在DB之前正常的读和写操作。
三、数据优先级
Vampire将从不同的数据源获取数据。不同的数据源将在某个数据中提供多个字段。不同数据源的数据质量是不同的,也就是说,不同数据源的数据是相同的。多个字段具有不同的优先级,优先级高的数据具有高质量。这个优先级是在访问数据源时定义的。因此,在更新数据时,也需要根据数据的优先级来判断数据是否被更新。目前,相同数据的相同字段只有一个数据源,因此可以先忽略这个问题。
Write接口的性能
Read接口目前主要是从DB中读取数据,其性能主要取决于以下两个方面的因素:
一、数据库表结构的设计
在设计过程中最小化数据冗余,将每个原始数据表垂直拆分为多个数据表,并根据业务需求构建索引,以便为每个查询的SQL语句建立索引。对于复杂的SQL查询,分成多个简单的SQL,然后让每一个简单的SQL索引,和重用这些尽可能简单的SQL,如果一个特定的SQL查询的结果将更大,需要分页,那么它将通过分析执行SQL来确定一个合理的页面大小。对于复杂查询和分页查询,通过执行一些简单的SQL方法来执行多个数据。
二、接口的设计
外部读取接口在设计上也尽可能简单。这里的简单性包括简单的输入和简单的返回值。简单的输入意味着在调用接口中传递的参数越小越好,每个传入的参数都是必需的。例如,一个接口有三个参数A、B和C,假设同时采用了A和C。这些参数可以间接推导出B参数。在这种情况下,B参数是不必要的,应该删除。返回值仅仅意味着返回的消息并不太多。它在设计上通常小于4 KB,并在消息中返回。数据字段都很有用。在分割整个接口的过程中,有两个重要的因素需要考虑:
1)是否所有接口都可以通过多个调用组合来获取数据库中所有有用的数据;
2)要完成一个特定的函数,需要尽可能少地调用多个简单的接口。尽量调用响应快的接口,调用响应慢的接口。在单个机器4核心4 g, Tomcat连接数字200,DB连接100号环境中,当数据量是1千瓦+读接口直接访问数据库,不需要缓存,对于一个简单的查询每秒可以达到1400 +,对于复杂的多个条件分页查询每秒可以达到400 +
3、Service
根据业务需求分析,每条生产线的SEO页面由几组页面组成。每一组页面都从不同的角度进行推广。每个页面由多个模块组成,一个模块对应一个接口。以机票为例:机票的SEO页面将包含两组页面,出发地点和机场。该页面集由A、B、C三个模块组成。机场页面由B、C、d三个模块组成。此时只需要开发4个接口即可实现对应于A、B、C、D四个模块的功能,提高了接口的可重用性。同时,您还可以在页面中配置一个模块,以显示不同语言、货币、城市和其他维度的不同数据。
4、Page
该项目主要由前端团队负责,这里不做详细描述。
5、Portal
它主要由4个模块组成。配置模块可以根据不同的语言和货币进行配置,控制服务中各个接口在不同参数下的返回结果和排序方法。日志模块主要用于记录吸血鬼的数据。更新进度、更新持续时间和日志;AB测试模块主要与配置模块协同工作,实现不同配置之间的比较,帮助业务人员做出更好的选择;统计模块主要用于统计Faba缓存的命中率。性能数据
总结
SEO项目的核心在于数据,如何收集数据,更新数据,并在每次更新中逐步沉淀出质量更好的数据。接口和数据表的设计尽量简单,以提高整个项目的性能。本文仅简要介绍了SEO项目重构的总体解决方案。设计方案中的具体实现细节描述不多,一些非核心功能还在开发中。有兴趣的学生可以留言。欢迎大家来拍砖。











评论 (0人参与)
最新评论